Build agents that operate on real data
Onyx AI lets you build workflow-driven agents with direct access to structured data, relationships, and documents. Documents can be uploaded and websites can be crawled, but Onyx stands apart because agents can search and compute over live structured data with the same fidelity as your production systems.
Structured data is the foundation
Query tables directly, filter and aggregate live data, and compute answers—then enrich with documents only when needed.
Agent Builder workflow trees
Replace prompt chains with inspectable workflow trees where each step performs a deliberate action with tool access.
Documents as supporting context
Upload PDFs and exports so agents can cite and enrich responses, without turning documents into your source of truth.
Outputs you can reuse
Produce datasets, computed metrics, narrative explanations, and visualization-ready outputs that chain into future workflows.
Documents and websites become inputs, not the system
Upload documents and crawl domains to provide supporting context. Structured data remains the foundation for grounded, current answers.
Document ingestion (supporting context)
Upload PDFs, spreadsheets, HTML exports, and knowledge articles so your agents can cite and enrich answers without turning documents into your source of truth.
Automated website crawling
Crawl a domain on a schedule and keep policy hubs, help desks, and marketing sites indexed as they change—without manual exports or sync work.
Knowledge search & references
Index files and crawled pages so agents can retrieve relevant passages and return grounded responses backed by searchable references.
Live structured data context
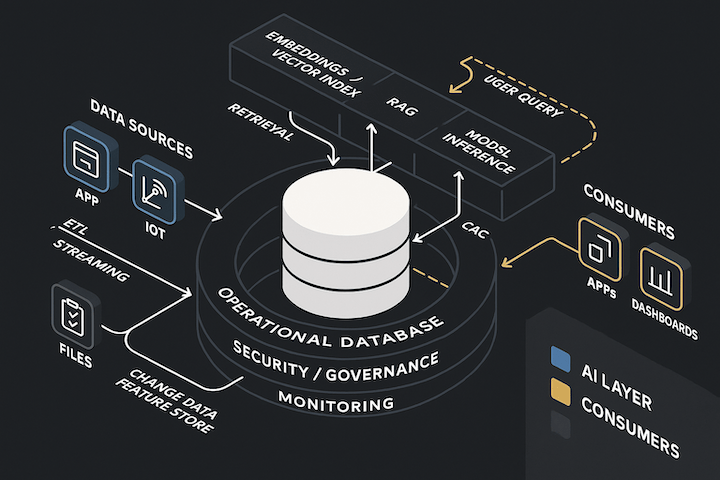
Blend documents with direct database querying so responses stay current and reflect the real state of your system—without ETL or stale snapshots.
Workflow-driven agents with direct access to structured data
Onyx agents don’t just retrieve text—they execute plans: query tables, traverse relationships, and produce reusable outputs.
Agent Builder (workflow trees)
Design agents as explicit workflow trees. Each node performs a deliberate step and can call tools to query, traverse, and compute over your Onyx data.
Structured data search (the foundation)
Agents can search tables directly—filter, aggregate, and compute on live structured data—then enrich with documents only when it adds value.
Relationship-aware execution
Traverse resolver-defined relationships to pull connected context across your model without stitching graphs over the network or relying on brittle joins.
Tool execution with governance
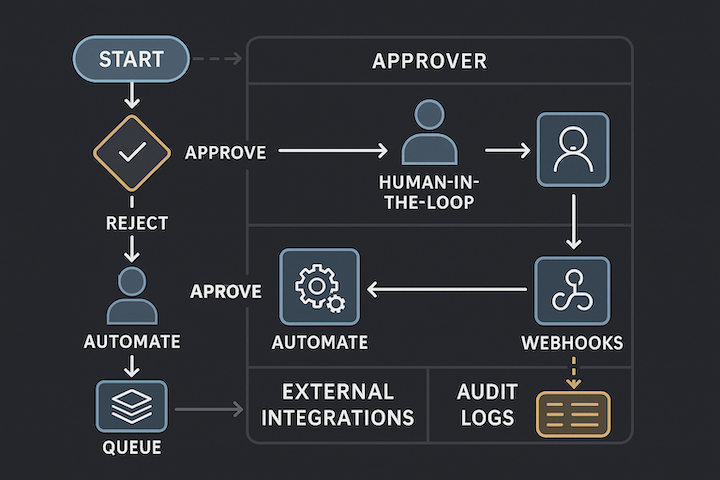
Give agents tool access to your data with the same approvals, visibility, and audit trails you use across Onyx Cloud.
Synthesis and outputs
Produce reusable artifacts—not just answers: computed metrics, structured datasets, narrative explanations, and visualization-ready outputs.
Outcomes across every team
Build agents that compute answers from live structured data, with documents used only as supporting context.
Startups & small businesses
- Ship an internal or customer-facing assistant grounded in live structured data, with documents used as supporting context.
- Replace brittle prompt chains with workflow trees that are inspectable, testable, and reusable across your team.
- Move fast without building a separate search or RAG pipeline just to keep answers current.
Growing revenue teams
- Surface account health, usage, and lifecycle events by querying live telemetry instead of relying on stale dashboards.
- Generate briefings and follow-ups informed by structured data and enriched with the right docs when needed.
- Share durable outputs across teams—workflows, datasets, and narrative summaries—rather than one-off chats.
Enterprise operations
- Keep policies and portals searchable via crawling and ingestion, while still treating the database as the system of record.
- Empower operations leads with agents that can compute answers over structured data and explain exactly how they arrived there.
- Apply governance consistently across agents, tools, and data access in one platform.
Put agents to work across your system
From support and analytics to investigations and briefings—agents compute on live data and produce reusable artifacts.
Internal business assistant
Answer operational questions by querying live structured data, then enrich with policy docs, runbooks, and knowledge articles when relevant.
Sales & success intelligence
Compute account health, adoption milestones, and next-step recommendations from live data—no manual dashboard building required.
Product research agent
Aggregate feedback, tickets, and usage analytics, then generate structured summaries and prioritized recommendations as reusable outputs.
Operational investigation
Trace incidents through connected data, traverse relationships, and produce a clear narrative backed by the exact queries and references used.
Knowledgebase enrichment
Continuously ingest documents and crawl sites so agents can cite the latest materials—without turning documents into your primary data model.
Executive briefing generator
Generate weekly KPI briefs that pair narrative insight with computed metrics pulled directly from live structured data.
Built for agents that operate on reality
Onyx makes structured data queryable by tools, relationships traversable by design, and workflows reusable—so agents can do real work.
Structured data first
Most AI platforms stop at document search. Onyx agents compute answers by querying live structured data and traversing relationships, then use documents as enrichment.
Agents as workflows, not prompts
Define behavior explicitly with workflow trees. Each step is inspectable, reusable, and grounded in tool execution against your real data model.
Database-native execution
Resolvers execute inside the database system. Graph attachment happens at the model level—without stitching graphs over the network.
Integration everywhere
Invoke agents through REST APIs, WebSockets, SDKs, background jobs, or application hooks—so AI becomes part of your system, not a separate tool.
Ready to build your first agent?
Create an Onyx workspace, upload supporting documents if you have them, and start building workflow-driven agents that query live structured data and produce reusable outputs.